Using buzzr to handle buzzdetect data
buzzr.RmdThis vignette is a comprehensive guide for using buzzr to manipulate buzzdetect result files. buzzr is a companion package to buzzdetect, a tool for passive acoustic monitoring of pollinators. For details about running buzzdetect itself, see the buzzdetect documentation. For a broader walkthrough of bioacoustic analysis with buzzdetect and buzzr, see the walkthrough here.
TL;DR
The core buzzr functionality is wrapped into a single function,
buzzr::bin_directory. This function reads all buzzdetect
results in a folder (recursively), translates the file times (audio
timestamps in seconds) to date-times (e.g. “January 1, 2000 12:42 PM”),
applies thresholds to turn neuron activations into detections, and bins
detections according to their start time.
Here’s an example:
df <- buzzr::bin_directory(
dir_results=system.file('extdata/five_flowers', package='buzzr'),
thresholds = c(ins_buzz=-1.2),
posix_formats = '%y%m%d_%H%M',
dir_nesting = c('flower','recorder'),
tz = 'America/New_York',
binwidth = 20
)## Grouping time bins using columns: flower, recorder
head(df)## flower recorder bin_datetime detections_ins_buzz frames
## <char> <char> <POSc> <int> <num>
## 1: chicory 1_104 2025-07-04 00:00:00 1 1250
## 2: chicory 1_104 2025-07-04 00:20:00 4 1250
## 3: chicory 1_104 2025-07-04 00:40:00 3 1250
## 4: chicory 1_104 2025-07-04 01:00:00 2 1250
## 5: chicory 1_104 2025-07-04 01:20:00 0 1250
## 6: chicory 1_104 2025-07-04 01:40:00 0 1250Dataset
For this walkthrough, we will use the buzzdetect results included with this package. The results correspond to some of the recordings described in the buzzdetect manuscript. Recorders were placed by five flowers in bloom (chicory, mustard, pumpkin, soybean, and watermelon) and allowed to record for 24 hours. The resulting audio was analyzed buzzdetect; we’ll refer to the resulting dataset as the “Five Flowers” dataset. To keep the buzzr version of the dataset light, we have retained only a single recorder from each plant and trimmed down the files. Find the full dataset in the Zenodo repository.
Locating the dataset
The path to the Five Flowers dataset on your machine can be retrieved
with the system.file function. Let’s have a look.
library(buzzr)
dir_data <- system.file('extdata/five_flowers', package='buzzr')
paths_results <- list.files(
dir_data,
recursive=T
)
head(paths_results)## [1] "chicory/1_104/250704_0000_buzzdetect.csv"
## [2] "mustard/54/240904_0000_buzzdetect.csv"
## [3] "pumpkin/1_37/240808_0000_buzzdetect.csv"
## [4] "soybean/9/230809_0000_buzzdetect.csv"
## [5] "watermelon/1_73/240727_0000_buzzdetect.csv"Here we see that the results are stored in folders according to the
pattern flower/recorder_id/HHMMDD_MMSS_buzzdetect.csv.
Results file structure
Let’s look at a single results file using base R:
path_results <- file.path(dir_data, paths_results[1])
df_base <- read.csv(path_results)
head(df_base)## start activation_ins_buzz activation_ambient_rain activation_ins_trill
## 1 0.00 -1.7 -2.0 -1.9
## 2 0.96 -2.0 -2.0 -1.9
## 3 1.92 -2.1 -2.8 -2.8
## 4 2.88 -2.0 -2.6 -2.4
## 5 3.84 -2.0 -2.3 -2.4
## 6 4.80 -1.8 -1.5 -1.6
## activation_mech_plane
## 1 -2.2
## 2 -2.4
## 3 -3.4
## 4 -3.2
## 5 -2.5
## 6 -2.3We have a start column and the activations for a few different neurons. Each row is a single frame, which is a 0.96s span of audio for these results.
Reading results
Result files can be well over a hundred thousand rows long, so
read.csv is quite slow. Let’s try buzzr instead, which
leverages data.table::fread. The function we want is
buzzr::read_results
df_buzzr <- buzzr::read_results(path_results)
head(df_buzzr)## start_filetime activation_ins_buzz activation_ambient_rain
## <num> <num> <num>
## 1: 0.00 -1.7 -2.0
## 2: 0.96 -2.0 -2.0
## 3: 1.92 -2.1 -2.8
## 4: 2.88 -2.0 -2.6
## 5: 3.84 -2.0 -2.3
## 6: 4.80 -1.8 -1.5
## activation_ins_trill activation_mech_plane
## <num> <num>
## 1: -1.9 -2.2
## 2: -1.9 -2.4
## 3: -2.8 -3.4
## 4: -2.4 -3.2
## 5: -2.4 -2.5
## 6: -1.6 -2.3You can see that buzzr renamed the default “start” column to the buzzr convention of “start_filetime”. This allows buzzr to distinguish between timestamps for file-time (as seconds from the start of file) and timestamps for real-world time (as date-time).
Using buzzr to interpret date-time
We can use buzzr to interpret the date-time of a recording from the name of the results file. For this, we need several more arguments.
posix_formats: A string (or vector of strings) containing the POSIX format code. Our files are saved with a 2-digit year, 2-digit month, 2-digit day, underscore, 24-hour hour, and minute. That is, “YYMMDD_HHMM”. The way to write this as a POSIX format string is:
%y%m%d_%H%M.first_match: If multiple POSIX format strings are supplied and the file matches multiple formats, should the first match be used (TRUE) or should NA be returned (FALSE, default)? This is won’t be needed if you’re working with a single file, but if you have multiple format (perhaps from using different recorders in the same experiment), this allows
read_directoryorbin_directoryto read all of the results in one go.drop_filetime: Should the output results retain the start_filetime column alongside start_datetime (FALSE) or should it be dropped (TRUE)? Note: this argument is only respected if POSIX formats are given. File-time will not be dropped if there is no other time column.
tz: The time zone to use for the POSIX translation. Required if translating results to date-time. Should match the time zone of the recordings. Time zones are a real nightmare. If you’re finding everything is plotting incorrectly, it’s probably a time zone issue.
Date-time data are unfortunately cumbersome, but you should only have to figure out these settings once per project.
df_datetime <- buzzr::read_results(
path_results,
posix_formats = '%y%m%d_%H%M', # YYMMDD_HHMM
first_match = FALSE, # doesn't matter in this case, since we have only one format
drop_filetime = FALSE, # keep the start_filetime column (by default, it's dropped)
tz='America/New_York' # the time zone these data were collected in
)
head(df_datetime)## start_datetime start_filetime activation_ins_buzz
## <POSc> <num> <num>
## 1: 2025-07-04 00:00:00 0.00 -1.7
## 2: 2025-07-04 00:00:00 0.96 -2.0
## 3: 2025-07-04 00:00:01 1.92 -2.1
## 4: 2025-07-04 00:00:02 2.88 -2.0
## 5: 2025-07-04 00:00:03 3.84 -2.0
## 6: 2025-07-04 00:00:04 4.80 -1.8
## activation_ambient_rain activation_ins_trill activation_mech_plane
## <num> <num> <num>
## 1: -2.0 -1.9 -2.2
## 2: -2.0 -1.9 -2.4
## 3: -2.8 -2.8 -3.4
## 4: -2.6 -2.4 -3.2
## 5: -2.3 -2.4 -2.5
## 6: -1.5 -1.6 -2.3Now we can see we’ve successfully translated the file-time to a date-time. “start_filetime” is present as before (since chose not to drop it), but we also have “start_datetime” holding the date-time. Usually you only care about the date-time, but file-time can be useful. For example, we could find frames with detected buzzes and use FFmpeg to extract the audio from the corresponding file times.
Using buzzr to interpret file structure
You’ll probably find it convenient to organize your recordings according to some schema. For example, in this dataset we placed recordings in folders corresponding to the recorder ID and placed those folders into ones corresponding to plant type. buzzr lets us extract information from the file path. We can do this with two arguments:
- dir_nesting: A character vector used to name the directory levels above the results file. That is, what does each level above the results represent? Each element becomes a column in the output, storing the components of the path for each data file.
-
return_ident: available in
read_directoryandbin_directory, should the file identifier be placed into its own column? The ident is the relative path from the results directory to the file, stripped of its extension and the_buzzdetecttag. You probably won’t care about this unless you want to pin down a specific problematic recording. For example, if you see a large spike of positives at 3:00AM, you may want to investigate.
df_nesting <- buzzr::read_results(
path_results,
dir_nesting = c('flower', 'recorder')
)
head(df_nesting)## flower recorder start_filetime activation_ins_buzz activation_ambient_rain
## <char> <char> <num> <num> <num>
## 1: chicory 1_104 0.00 -1.7 -2.0
## 2: chicory 1_104 0.96 -2.0 -2.0
## 3: chicory 1_104 1.92 -2.1 -2.8
## 4: chicory 1_104 2.88 -2.0 -2.6
## 5: chicory 1_104 3.84 -2.0 -2.3
## 6: chicory 1_104 4.80 -1.8 -1.5
## activation_ins_trill activation_mech_plane
## <num> <num>
## 1: -1.9 -2.2
## 2: -1.9 -2.4
## 3: -2.8 -3.4
## 4: -2.4 -3.2
## 5: -2.4 -2.5
## 6: -1.6 -2.3This isn’t terribly useful if we’re dealing with a single file, but
it’s very convenient when we read an entire
directory. However, your file structure must be
rectangular! That is, every file has to have the same level of nesting.
Having both foo/bar/results.csv and
foo/bar/lorem/results.csv won’t work.
Calling detections
Raw neuron activations are not useful by themselves; a threshold must be applied to convert the activations into discrete detections. The threshold at which to call detections depends on the model you’re using and how you want to balance the detection sensitivity against the false positive rate. We recommend using a threshold with 95% precision (95% of called buzzes are true) as a starting point, but you may want to fine-tune if detections are low or if there are sources of false positives in your audio.
For model_general_v3, a threshold of -1.2 is a good starting point for calling buzzes. This threshold should roughly correspond to 95% precision. Activations above this value will count as detected instances of buzzing. For this vignette, we’ll also try detecting planes with a threshold of -2. This threshold is arbitrary and untested, but it will let us see how buzzr handles multiple detection columns.
We can call detections by applying the function
buzzr::call_detections to a results data frame that has
neuron activations. call_detections takes one argument in
addition to the results data frame:
- thresholds: a named numeric vector with names corresponding to the neurons to be binned and the values corresponding to the desired threshold.
df_called <- buzzr::call_detections(
df_datetime,
thresholds = c(
ins_buzz = -1.2,
mech_plane = -2
)
)
head(df_called)## start_datetime start_filetime detections_ins_buzz detections_mech_plane
## <POSc> <num> <lgcl> <lgcl>
## 1: 2025-07-04 00:00:00 0.00 FALSE FALSE
## 2: 2025-07-04 00:00:00 0.96 FALSE FALSE
## 3: 2025-07-04 00:00:01 1.92 FALSE FALSE
## 4: 2025-07-04 00:00:02 2.88 FALSE FALSE
## 5: 2025-07-04 00:00:03 3.84 FALSE FALSE
## 6: 2025-07-04 00:00:04 4.80 FALSE FALSEWe can see that we retain our two time columns, but any “activation_” columns named in our thresholds have been replaced with “detections_”. Neurons without a threshold have been dropped.
The detections are binary TRUE/FALSE values. You may be interested in the total number of detections, in which case we could simply sum the column.
## [1] 2604Across the whole day, we saw 2,604 detections out of 90,000 frames for an average detection rate of 0.03.
While total detection rates are valuable in some cases, a more common interest is the change in detection rate over time. For that, we need to bin.
Binning
To bin detections by time, we can apply the function
buzzr::bin to a results data frame that has called
detections. bin only needs two arguments in addition to the
data frame:
- binwidth: the size of the bin in minutes
- calculate_rate: do you want buzzr to automatically calculate detection rates (detections/frames) for the detection columns? While it might seem like this would always be desired, sometimes you want to modify the binned results multiple times. E.g., first bin with a width of 1 to compress your data, then bin with a width of 15 for graphing and a width of 60 for statistical analysis. In this case, you might as well save the rate calculation for the end.
df_bin <- buzzr::bin(
df_called,
binwidth=15, # 15-minute bins
calculate_rate = TRUE # calculate our detection rates for us
)## Both filetime and datetime columns are present; dropping filetime columns in favor of datetime.
head(df_bin)## bin_datetime detections_ins_buzz detections_mech_plane frames
## <POSc> <int> <int> <num>
## 1: 2025-07-04 00:00:00 1 37 938
## 2: 2025-07-04 00:15:00 3 22 937
## 3: 2025-07-04 00:30:00 2 106 938
## 4: 2025-07-04 00:45:00 2 60 937
## 5: 2025-07-04 01:00:00 2 62 938
## 6: 2025-07-04 01:15:00 0 12 937
## detectionrate_ins_buzz detectionrate_mech_plane
## <num> <num>
## 1: 0.001066098 0.03944563
## 2: 0.003201708 0.02347919
## 3: 0.002132196 0.11300640
## 4: 0.002134472 0.06403415
## 5: 0.002132196 0.06609808
## 6: 0.000000000 0.01280683You can see that buzzr handled the file-time and the date-time each with no problem and now our detections have been turned from booleans to integers.
Let’s see what these data look like!
plot(
df_bin$bin_datetime,
df_bin$detections_ins_buzz
)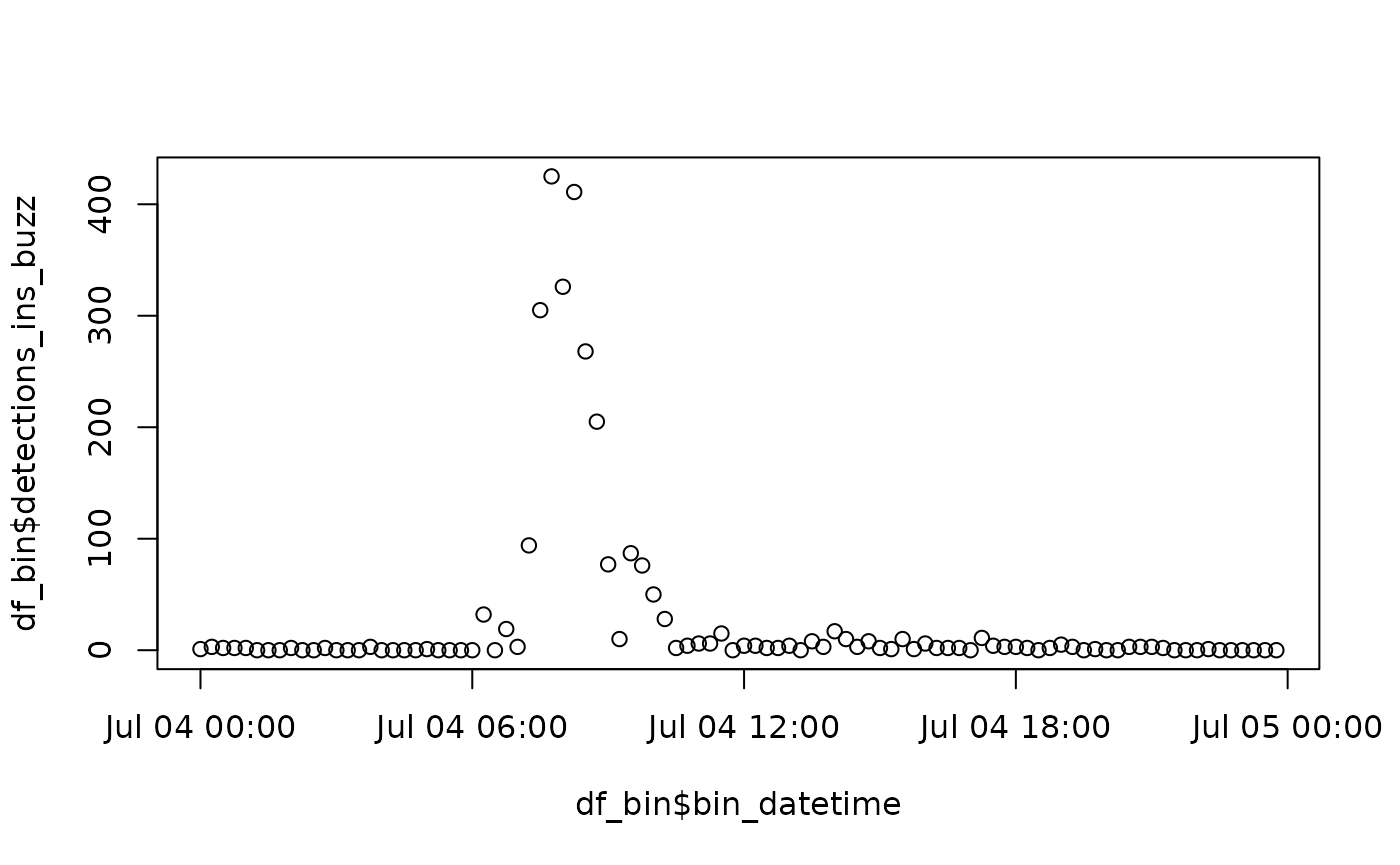
Cool! We see an obvious trend of buzz detections launching up in the early morning, then dropping off before midday. There are a few false positives at night, but they’re dwarfed by the signal from the daytime.
How buzzr identifies groups
When binning, buzzr drops columns for frame times, neuron activations, and detection rates. Then, for each bin, frame counts and total detections are summed. If requested, detection rates are also calculated. Every remaining column is used as a group for binning. This could cause unexpected results if you’ve created custom columns.
For example:
df_called$newcol <- rep(c('A', 'B'), nrow(df_called)/2)
df_bin_customgroups <- buzzr::bin(
df_called,
binwidth=15, # 15-minute bins
calculate_rate = TRUE # calculate our detection rates for us
)## Both filetime and datetime columns are present; dropping filetime columns in favor of datetime.## Grouping time bins using columns: newcolbuzzr prints a message showing all grouping columns just in case the groupings were unintended. Here we can see the bins contain half as many frames as we would have expected if we weren’t aware of the grouping logic.
head(df_bin_customgroups)## newcol bin_datetime detections_ins_buzz detections_mech_plane frames
## <char> <POSc> <int> <int> <num>
## 1: A 2025-07-04 00:00:00 1 16 469
## 2: B 2025-07-04 00:00:00 0 21 469
## 3: A 2025-07-04 00:15:00 1 11 469
## 4: B 2025-07-04 00:15:00 2 11 468
## 5: B 2025-07-04 00:30:00 2 56 469
## 6: A 2025-07-04 00:30:00 0 50 469
## detectionrate_ins_buzz detectionrate_mech_plane
## <num> <num>
## 1: 0.002132196 0.03411514
## 2: 0.000000000 0.04477612
## 3: 0.002132196 0.02345416
## 4: 0.004273504 0.02350427
## 5: 0.004264392 0.11940299
## 6: 0.000000000 0.10660981Reading entire directories
Binning a directory
All of the above steps can be completed for every file in a directory
(and all subdirectories) with a single command:
buzzr::bin_directory.
For this, we just combine all of the arguments we’ve seen before.
df_fullbin <- buzzr::bin_directory(
dir_results=dir_data,
thresholds = c(ins_buzz=-1.2),
posix_formats = '%y%m%d_%H%M',
first_match = FALSE,
drop_filetime = TRUE,
dir_nesting = c('flower','recorder'),
return_ident = TRUE,
tz = 'America/New_York',
binwidth = 20,
calculate_rate = TRUE
)## Grouping time bins using columns: flower, recorder
head(df_fullbin)## ident flower recorder bin_datetime
## <char> <char> <char> <POSc>
## 1: chicory/1_104/250704_0000 chicory 1_104 2025-07-04 00:00:00
## 2: chicory/1_104/250704_0000 chicory 1_104 2025-07-04 00:20:00
## 3: chicory/1_104/250704_0000 chicory 1_104 2025-07-04 00:40:00
## 4: chicory/1_104/250704_0000 chicory 1_104 2025-07-04 01:00:00
## 5: chicory/1_104/250704_0000 chicory 1_104 2025-07-04 01:20:00
## 6: chicory/1_104/250704_0000 chicory 1_104 2025-07-04 01:40:00
## detections_ins_buzz frames detectionrate_ins_buzz
## <int> <num> <num>
## 1: 1 1250 0.0008
## 2: 4 1250 0.0032
## 3: 3 1250 0.0024
## 4: 2 1250 0.0016
## 5: 0 1250 0.0000
## 6: 0 1250 0.0000## [1] "chicory" "mustard" "pumpkin" "soybean" "watermelon"Rebinning only requires a single command!
## Grouping time bins using columns: flower, recorder## ident flower recorder bin_datetime
## <char> <char> <char> <POSc>
## 1: chicory/1_104/250704_0000 chicory 1_104 2025-07-04 00:00:00
## 2: chicory/1_104/250704_0000 chicory 1_104 2025-07-04 02:00:00
## 3: chicory/1_104/250704_0000 chicory 1_104 2025-07-04 04:00:00
## 4: chicory/1_104/250704_0000 chicory 1_104 2025-07-04 06:00:00
## 5: chicory/1_104/250704_0000 chicory 1_104 2025-07-04 08:00:00
## 6: chicory/1_104/250704_0000 chicory 1_104 2025-07-04 10:00:00
## detections_ins_buzz frames
## <int> <num>
## 1: 10 7500
## 2: 7 7500
## 3: 1 7500
## 4: 878 7500
## 5: 1460 7500
## 6: 111 7500Reading a directory
You may also want to read a directory without binning the results. For example you may want to try out multiple different thresholds efficiently, or maybe you want to extract all positive frames, or examine the behavior of activation values.
The function for this is buzzr::read_directory, and it
behaves how you expect given the information above.
df_fullread <- buzzr::read_directory(
dir_results=dir_data,
posix_formats = '%y%m%d_%H%M',
first_match = FALSE,
drop_filetime = TRUE,
dir_nesting = c('flower','recorder'),
return_ident = TRUE,
tz = 'America/New_York'
)
nrow(df_fullread)## [1] 450000